Measuring the Semantic Accessibility Gap in LLM-Generated Web UIs



Abstract
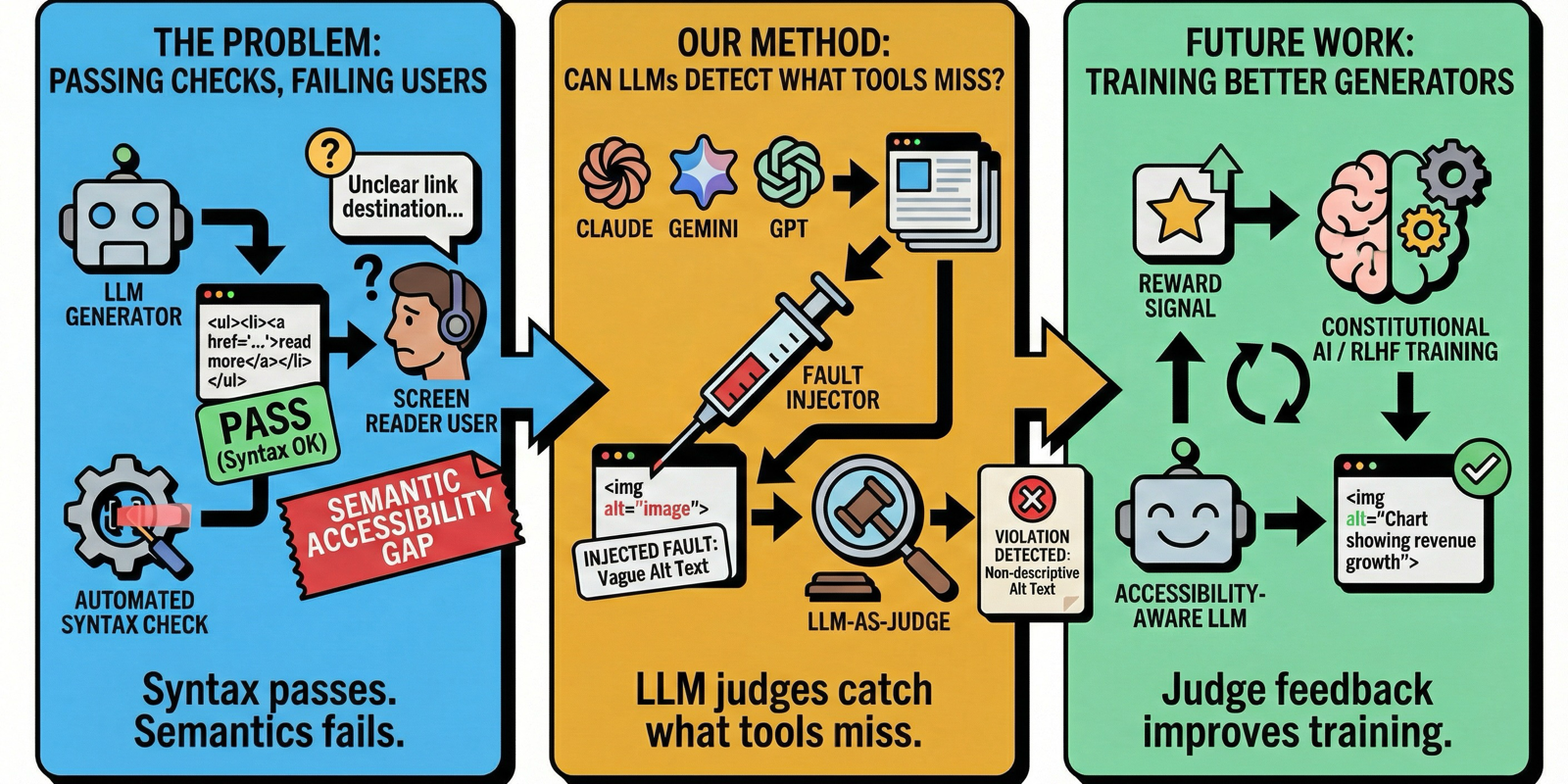
Large Language Models are increasingly used to generate web interfaces from natural language specifications. Automated accessibility tools evaluate these interfaces by detecting syntactic violations such as missing attributes, but cannot assess whether accessibility content is actually meaningful — an image with alt="image" passes every check yet conveys nothing to screen reader users. We investigate the prevalence of such semantic accessibility violations in LLM-generated interfaces. Analyzing 300 UIs produced by three commercial models, we identify 541 semantic violations across six fault types. We validate an LLM-as-judge approach through controlled fault injection, achieving recall rates of 80–92%, and triangulate with a preliminary human annotation study. Our findings suggest that LLM judges can extend accessibility evaluation into the semantic dimension that automated tools miss, opening opportunities for their integration as reward signals in accessibility-aware development workflows.
BibTeX
@inproceedings{calo2026semacces,
author = {Tommaso Calò and Alexandra-Elena Guriţă and Luigi De Russis},
title = {Measuring the Semantic Accessibility Gap in LLM-Generated Web UIs},
booktitle = {Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems (CHI EA '26)},
year = {2026},
address = {Barcelona, Spain},
publisher = {ACM},
doi = {10.1145/3772363.3799364},
url = {https://doi.org/10.1145/3772363.3799364}
}