Enhancing smart home interaction through multimodal command disambiguation


Abstract
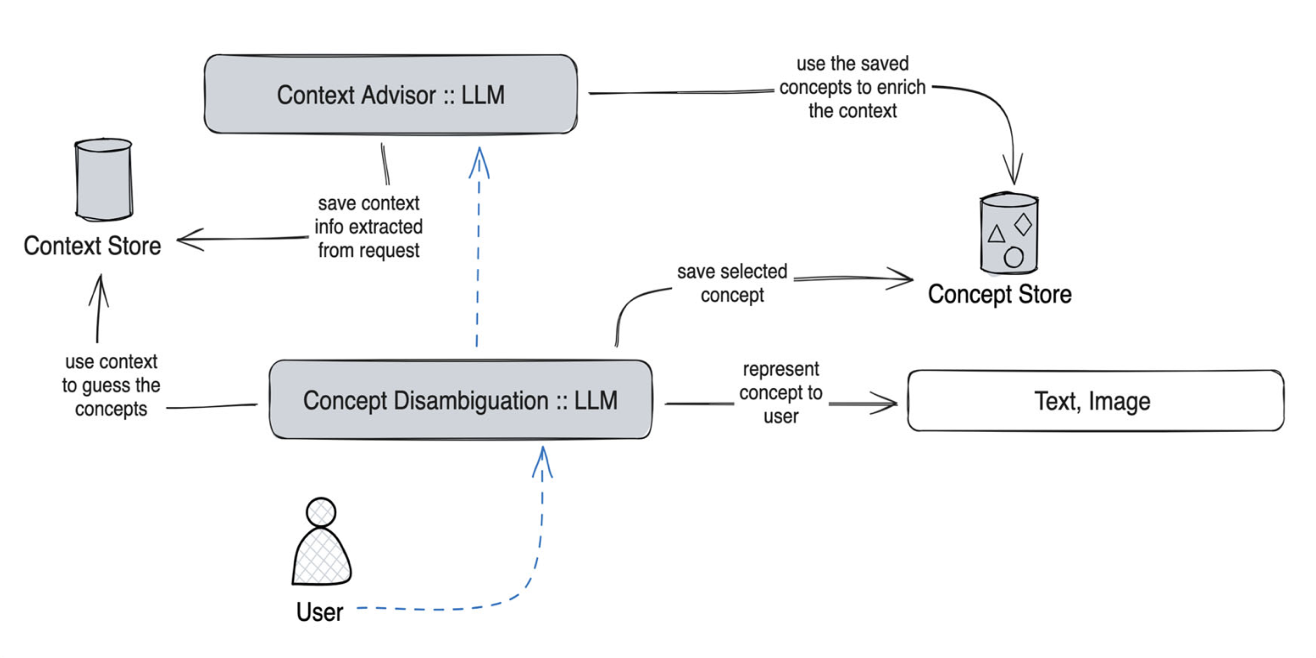
Smart speakers are entering our homes and enriching the connected ecosystem already present in them. Home inhabitants can use those to execute relatively simple commands, e.g., turning a lamp on. Their capabilities to interpret more complex and ambiguous commands (e.g., make this room warmer) are limited, if not absent. Large language models (LLMs) can offer creative and viable solutions to enable a practical and user-acceptable interpretation of such ambiguous commands. This paper introduces an interactive disambiguation approach that integrates visual and textual cues with natural language commands. After contextualizing the approach with a use case, we test it in an experiment where users are prompted to select the appropriate cue (an image or a textual description) to clarify ambiguous commands, thereby refining the accuracy of the system’s interpretations. Outcomes from the study indicate that the disambiguation system produces responses well-aligned with user intentions, and that participants found the textual descriptions slightly more effective. Finally, interviews reveal heightened satisfaction with the smart-home system when engaging with the proposed disambiguation approach.
BibTeX
@article{calo2024enhancing,
title={Enhancing smart home interaction through multimodal command disambiguation},
author={Cal{\`o}, Tommaso and De Russis, Luigi},
journal={Personal and Ubiquitous Computing},
pages={1--16},
year={2024},
url = {https://doi.org/10.1007/s00779-024-01827-3},
doi = {10.1007/s00779-024-01827-3},
publisher={Springer}
}